


Back to the Tractatus: Resurrecting Early Wittgenstein [SERIOUS]
There aren't that many universes that contain Wikipedia
"You shall know a word by the company it keeps." - J.R. Firth, A Synopsis of Linguistic Theory 1930-1955, 1957
"The limits of my language mean the limits of my world." - Ludwig Wittgenstein, Tractatus Logico-Philosophicus (5.6), 1921
"Whereupon one cannot speak, thereof one must be silent” - Ludwig Wittgenstein, Tractatus Logico-Philosophicus, 1921
“If a lion could speak, we could not understand him.”
Formal languages — mathematics, code — are powerful because their precision allows them to perfectly mirror systems. But this is also their crux, because building complex systems from simple parts is hard. That’s why analytic philosophy, in grappling with the most general questions, builds on natural languages intead.
But proving statements couched in natural language is hard. In math, verifying proofs is easy because relationships between objects like numbers are governed by deterministic rules like addition and multiplication. With natural languages, by contrast, fundamental objects like nouns and verbs have extremely complicated and context dependent relationships with each other. Moreover, grammatical sentences can be nonsensical, as demonstrated by Chomsky’s famous “Colourless green ideas sleep furiously” sentence.
Enter the young Ludwig Wittgenstein with his legendary Tractatus Logico-Philosophicus (1921), which aimed to formalise natural languages to eliminate such sentences as ungrammatical in the same way as 2-1=7. Success would mean philosophy, couched in natural language, would wield the precision of mathematics, completing Aristotle’s quest to formalise logic.
The Tractatus’ thesis is best summarised by its “picture theory” of language, which holds that propositions derive meaning by having a syntactical structure that maps onto the potential structure of reality, ruling out nonsense like sleeping ideas.
For instance, in the proposition "The cat is on the mat," “cat” and “mat” represent objects while "is on" depicts the spatial relationship between them. If this accurately reflects the world, the proposition is true; otherwise, it is false.
So far, so good. But consider sentences like "I felt sorry for him." Mapping abstract verbs and nouns like felt and sorry to concrete images is tricky. Are we really to accept that feeling sorry is as senseless as sleeping ideas?
Examined closely, the same issue plagues the cat example. “Cats” are abstractions of cute, meowing, fluffy things that we can see, hear and touch; linguistically enumerating all associations and consequences conjured by “cat,” let alone “felt” and “sorry,” seems impossible, giving rise to the symbol grounding problem — the question of how words get their meaning.
For these reasons, an older Wittgenstein abandoned the Tractatus’ dream of finding a road from language to reality, coming to view natural languages as inherently ambiguous. Languages evolved for efficient communication, with no need to spell out that which is implicit in our shared history and context — common sense.
Until recently, near everyone was a late Wittgensteinian. But it’s hard to argue large language models don’t validate the early Wittgenstein, bringing us back towards the Tractatus and challenging the notion that we need sensory experience to ground the meaning of words.
Consider Othello-GPT, a model trained on the namesake board game in which two players place black or white counters to compete for territory. By representing games as sequences of moves (E8, D6, B5,…) — “words” — the authors trained a neural network by having it repeatedly play guess-the-next-move on partial game sequences, gradually nudging its parameters to increase confidence in good guesses and decrease confidence in bad guesses (i.e. the same procedure used to train ChatGPT.)
Peeking inside the neural network to see what it learned, they found it represented the game geometrically, with counters in the correct positions on an 8x8 grid. This is remarkable, like a blind man learning to visualise chess after hearing game sequences. Moreover, Othello-GPT used the grid representations intelligently, changing its strategies without violating rules whenever the experimenters jumbled its inner representations to correspond to different board states, even when this produced illegal formations never seen in training.
This is irreconcilable with the simplified view that language models are “just” statistical next-word predictors that don’t understand. Learning to predict the next state requires understanding the game.
Though compelling, Othello is limited. Any sequence of the 64 “words” maps to a single board state, conforming to Wittgenstein’s picture theory. Visual understanding from text — semantics from syntax — is not fully convincing here.
But it turns out natural language models like those powering ChatGPT can visualise the world too. This paper, for instance, shows language models trained on text can describe images! (Figure 1)

Figure 1: Language models can capture images with no further training!
Let’s dissect how this works. First, language models have no “eyes.” They are trained to process sequences and so can’t interpret raw images out of the box. But images can be compressed into sentence-like sequences before being fed to the language model. If the compression relies on information from the images alone, there’s no danger of linguistic information leaking into the sequences.
To achieve this, the authors first trained a vision model (BEiT) to reconstruct images where patches had been artificially removed. This model comprises an encoder, which learns to compress images into concise sequences capturing essential elements (like a dog, ball, and park, ignoring individual blades of grass), and a decoder, which learns to reconstruct the original image's rich detail from this sequence. Successful reconstruction indicates the compression captured the core visual concepts.
After training BEiT, the researchers fed images into its encoder, generating sequences of vectors corresponding to sequential patches of the image. These visual sequence vectors were then mapped into the input space of a language model (GPT-J) using a linear intermediate model before being fed through the language model for captioning. The linear part of the model was fine-tuned on ground-truth image captions to optimise the captions of the language model.
The linearity of this intermediate step is crucial to understanding why this isn’t a way of cheating by teaching the language model vision directly. To see why, note that a good caption, like "A brown dog happily chases a red ball across a grassy field," requires a holistic understanding of the scene. It’s not enough to identify tokens corresponding to "dog," "ball," and "grass" independently. The language model needs to understand the relationships and dependencies between these elements: the dog is the agent, the ball is the object, "chases" describes their interaction, "happily" describes the dog's state (inferred perhaps from posture), and "across a grassy field" provides the spatial context.
This holistic understanding relies on capturing the complex dependencies between the different image patches or tokens. The meaning and relevance of the "dog" token are heavily influenced by the presence and position of the "ball" token and the "grass" tokens. This is where the limitation of a linear mapping becomes stark. A linear model fundamentally works by applying fixed weights to its inputs and summing them. While it can learn which visual tokens generally correspond to which text concepts (e.g., "this patch pattern often maps to the word 'dog'"), it cannot effectively learn or represent the intricate, context-dependent relationships between those tokens. It struggles to capture rules like: "IF the 'dog' token shows a specific posture in relation to the 'ball' token's position, THEN the appropriate verb is 'chases'." Capturing these kinds of dynamic, interactive dependencies requires the powerful, non-linear processing capabilities of the deep neural networks within the vision encoder (which initially processes the image) and the language model (which ultimately generates the text).
Therefore, the linear intermediate model acts as a relatively simple translator. It cannot learn the holistic scene structure or the inter-token dependencies itself. It takes the sequence of image tokens, where the relationships and dependencies have already been implicitly encoded by the sophisticated vision model, and transforms it into a format the language model can accept, essentially aligning their representational spaces.
The language model then takes this structured input and leverages its own vast knowledge – gleaned entirely from patterns in text describing countless objects, actions, and relationships – to infer the most likely holistic scene and generate the appropriate caption. The success of this process underscores how much information about the structure of the world, including complex visual relationships and dependencies, is implicitly embedded within the statistical patterns of natural language. It's not just recognizing isolated concepts, but understanding how they typically interact, an understanding that LLMs can apparently derive from text alone.
Therefore, the language model, when generating captions, is still primarily leveraging the understanding of concepts and their relationships that it developed during its text-only training. The linear bridge simply allows the visually-derived concepts (already processed and structured by the vision model) to be fed into the language model's existing linguistic framework. This preserves the core finding: the language model utilizes its vast knowledge learned from text patterns to interpret and describe the structured visual information passed to it. This demonstrates that the language model can visualize the world to some extent, drawing on the statistical structure of language itself, which implicitly encodes vast amounts of information about the world, including visual aspects.
These steps produce useful image captions, proving language models can visualise the world when they’ve only ever lived in a text universe! Wittgenstein, then, was onto something with his picture theory: maps from syntax to semantics are possible. The nuance is that the meaning of a word is found in its usage patterns in language as a whole rather than in the structure of single sentences like “the cat is on the mat.”
Even 5 years ago, cognitive scientists balked at this, agreeing with the later Wittgenstein that natural language can only get meaning via senses.
But how on Earth can fancy auto-completers know what cats look like? At one level, the answer is that richer semantic understanding’s of the visual realm lead to better auto-completers. But this doesn’t explain why text is informative enough to learn this understanding.
Comprehending the magic, I think, begins by appreciating that although words are arbitrary symbols without context, their relationship with other words gives them context and, therefore, meaning. The linguist J.R. Firth put it best: "You shall know a word by the company it keeps."
Large Language Models are especially powerful in this regard because their Transformer architecture allows them to learn highly context-sensitive word representations. For example, on encountering the word “bank,” a language model can attend to a description of a scene describing a river many pages earlier, so it won’t confuse a river bank with a financial institution when deciding on probable completions.
Category Theory is the best framework to understand this formally, because it analyses objects (in this case, words) within a category (language) by focusing solely on their interrelationships. This puts constraints on the contents of the words, which considered alone are just arbitrary symbols. This partially explains how models can develop visual understandings of words without vision, overcoming the symbol grounding problem. After seeing enough text, transformers can represent words as complex networks of interrelationships, with relationship strengths expressing probabilities of subsequent words. With thousands of possibilities for subsequent words, these networks can take complex shapes. Figure 2 provides a schematic illustration, and the relevant paper is available here.

Figure 2: Enriched Category Theory allows us to understand how meaning is assigned to arbitrary words in language models. See here for slides, and here for (semi) accessible talk.
But just how many words does GPT-J have to see to visualise them? GPT-J was trained on The Pile, a 1,254.20 GiB corpus. Assuming 5 bytes per word, this means about 1,254.20 GiB * (1024 MiB/GiB) * (1024 KiB/MiB) * (1024 bytes/KiB) / (5 bytes/word) ~= 2.69 x 10^11 words. Putting this in context, kids hear about 1e6 words per month, so the average 20-year-old has heard about 20x1e6 = 2e8 words. So GPT-J was trained on ~2.69x10^11/2e8 =1345x more words than the average 20-year-old. A picture is worth a thousand words!
Ok, I fudged the calculation for poetic license. I could have added written language read by kids, or ignored code in GPT-Js training corpus, etc. But more critically, I glossed over the depth of GPT-Js visual understanding: captioning is imperfect, and one doesn’t need to understand details like textures of t-shirts to caption, so GPT-J’s visual undnerstanding isn’t as high-fidelity as ours.
Then again, GPT-J is tiny compared to modern LLMs, and more words likely means more fidelity. We don’t have numbers for GPT-4, but Google’s PaLM was trained on 1e12 words and has 90x more parameters than GPT-J, so who knows how well it understands the visual realm?
Whatever the answer, it’s clear that the map from language to reality is much better than almost anybody thought it would be. Wittgenstein’s picture theory is back in play! Still, do these findings extend beyond vision? It seems unlikely, given written language reflects the dominance of vision in our senses (Figure 3).
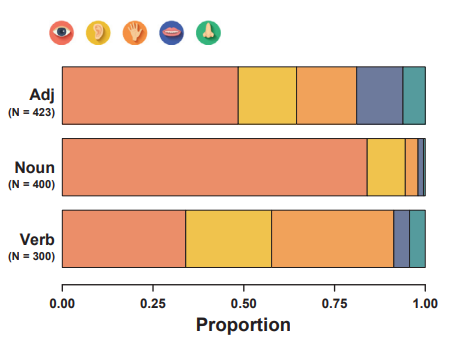
Figure 3: Natural language is biased by our visual dominance.
But recent research suggests that ChatGPT based similarity judgments are great for auditory (loudness) and visual content (colour), but less good for taste (Figure 4), matching what we’d expect for how much we rely on and talk about each modality (Figure 3).

Figure 3: LLMs have a nuanced understanding of the auditory word too, and even some understanding of taste!
There’s even evidence language models understand internal perceptions like emotions, and have something akin to a theory of mind (ToM). This was one of the hyperbolic claims of Microsoft’s controversial Sparks of AGI paper, which isn’t as ridiculous as it sounds: abstract language about things we can’t enact or point to is at least as common as concrete language, and we talk about emotions a lot (some of us, at least…). Recent work suggests LLMs, especially GPT-4, perform well on some ToM tasks, though obviously not as well as us.
Tying things up, we have a picture where language puts much higher constraints on possible universes than almost any skeptic or cognitive scientist thought it would. There just aren’t that many universes that could contain Wikipedia. Now, language models have many failure modes that look ridiculous to us, so we needn’t overstate this as indicating imminent AGI. But deflationary statements like “LLMs are just linguistic JPEGs” or “dumb next-word predictors” are just as if not more banal, and are an indication of being ignorant of the results outlined here. Indeed, these takes ironically evoke the feeling that one is talking to a language model!
Jokes aside, our incredulity at visual understanding in language models is anthropocentrism: we don’t learn this way, so it’s impossible. But we don’t have time to see trillions of words, and birds didn’t achieve heavier-than-air flight using jet engines. LLMs are yet another example of Rich Sutton’s bitter lesson that scalable dumb approaches beat non-scalable clever ones, and though I’m not ready to embrace the scaling hypothesis yet, it surprised me. And more to the point, it’s scientifically interesting that language says much more about us informative than we thought, counterweighting claims that the meaning of arbitrary symbols requires multimodal senses, and can’t be understood by reference to yet more arbitrary symbols1. Linguists rejoice! The world just got a little more Tractatus!
Note, language models do have some multimodal grounding e.g. natural language descriptions grounded by code. But this is nowhere near enough to explain the captioning ability of small language models GPT-J.